Model Training and Methodology#
This section outlines the methodology used to train the machine learning model for predicting heart disease.
Model Selection#
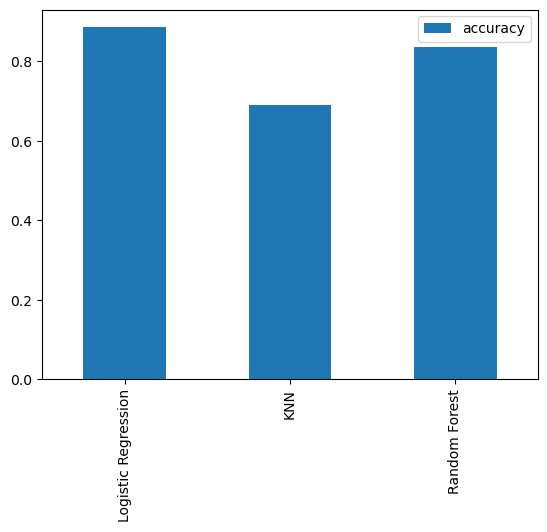
We experimented with several models, including Logistic Regression, K-Nearest Neighbors (KNN), CatBoost , XGBoost and Random Forest, to determine the most effective approach. As shown in the chart below, Logistic Regression emerged as the most robust model with an accuracy of over 0.88.
Data Preprocessing#
Handling Missing Values: Ensured there were no missing values in the dataset, as they could impact the model’s performance.
Model Training#
Data was split into training (80%) and testing (20%) sets to evaluate model performance effectively.
Cross-Validation: A 5-fold cross-validation strategy was used to ensure the model’s robustness and reduce overfitting risks.
Hyperparameter Tuning: Performed using:
RandomizedSearchCV to explore a wide range of hyperparameters efficiently.
GridSearchCV to fine-tune the most promising hyperparameter values identified earlier.
Note: Hyperparameter tuning was performed using RandomizedSearchCV initially, followed by a more exhaustive GridSearchCV to fine-tune the Logistic Regression model.
Model Evaluation#
The model was evaluated using several metrics, such as accuracy, precision, recall, and F1-score, as summarized in the classification report. Additionally, a confusion matrix was used to provide insights into the model’s predictive capabilities.